
This white paper unveils NXON.ai's engineering principles and implementation strategy that deliver high performance, scalability, and sustainability for sovereign AI cloud ecosystems.
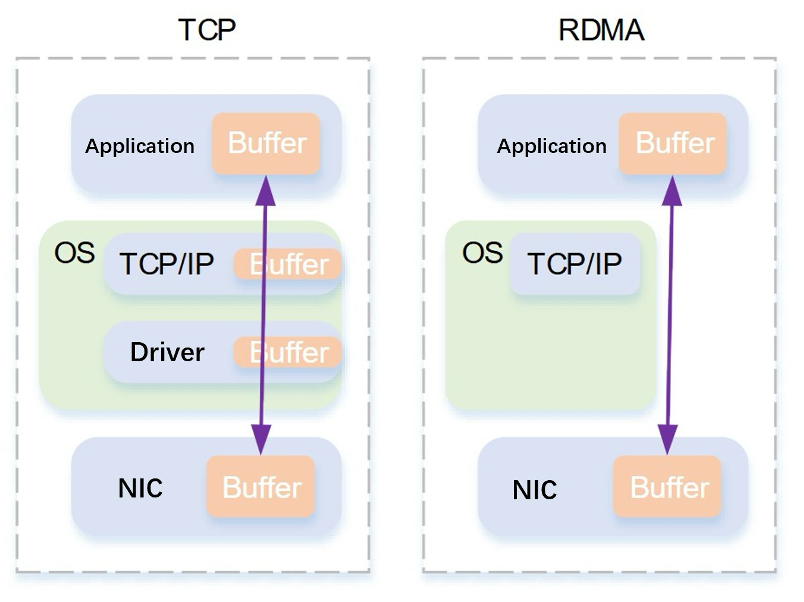
Training large language models (LLMs) with trillions of parameters demands synchronized communication between thousands of GPUs. Traditional TCP/IP networks introduce latency through CPU processing, context switching, and retransmission overhead, creating a bottleneck that limits scaling efficiency.
NXON.ai's solution: Integrate Remote Direct Memory Access (RDMA) to bypass CPU intervention, enabling direct data movement between GPU memories and reducing latency by orders of magnitude.
TCP vs RDMA Architecture Comparison
RDMA Protocol Comparison
| Protocol | Transport Layer | Ecosystem | Cost | Performance | Adoption |
|---|---|---|---|---|---|
| InfiniBand | Proprietary | Closed | High | Excellent+ | Limited |
| iWARP | TCP | Open | Medium | Weak | Declining |
| RoCEv2 | UDP/IP | Open Ethernet | Low | Excellent | Growing |
RoCEv2 achieves InfiniBand-like performance while maintaining Ethernet openness and flexibility—a decisive factor for scalable AI networks.
NXON.ai's data center architecture leverages RoCEv2 to achieve ultra-efficient interconnects for its 400G‒800G GPU clusters.
Key Benefits:
- •Open Standard: Interoperable across multi-vendor ecosystems.
- •Low Cost: Uses standard Ethernet hardware and software.
- •Scalable: Supports >32,000 ports in 800G networks.
- •Rapid Deployment: Lead time reduced to 1‒2 months.
- •Dynamic Latency Control: Consistent sub-5µs operational latency.
NXON.ai's RoCE network integrates:
- •PFC & ECN for lossless and efficient traffic management.
- •AI-driven Load Balancing (AILB) and Rate-Aware Load Balancing (RALB).
- •Telemetry-based Congestion Control with gRPC and NETCONF.
- •1:1 Oversubscription Ratio using 400G Ruijie RG-S6990-128QC2XS switches.
Performance Metrics:
- •97% bandwidth utilization
- •<5µs latency
- •128x400G per chassis
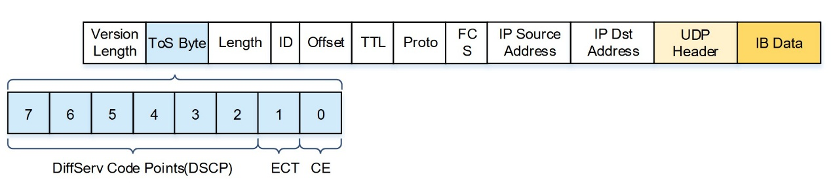
RoCEv2 Packet Header Structure
PFC and ECN Comparison
| Feature | PFC | ECN |
|---|---|---|
| Function | Stop traffic preemptively | Slow down senders intelligently |
| Scope | Hop-by-hop | End-to-end |
| Mechanism | Reactive pause | Proactive adjustment |
| Analogy | Traffic cop halting vehicles | GPS rerouting before congestion |
Together, these mechanisms maintain a perfect flow equilibrium across AI workloads.
NXON.ai monitors CNP and NAK packets for real-time congestion insight:
- •CNP (Congestion Notification Packets) trigger flow reduction before queue overflow.
- •NAK (Negative Acknowledgement) packets highlight retransmission causes.
These are continuously monitored via ERSPAN mirroring and gRPC streaming, enabling predictive maintenance and adaptive performance tuning.
In AI training and high-performance computing (HPC) environments, RoCEv2 enables deterministic performance under extreme workloads.
Use Cases:
- •Multi-node LLM training (1‒10 trillion parameters)
- •AIGC and multimodal inference
- •Scientific simulation and industrial rendering
Results:
- •Sub-5µs latency
- •97% link utilization
- •Zero-loss inter-GPU communication
Through the deployment of RoCEv2, NXON.ai transforms Ethernet into a high-performance, lossless backbone for AI infrastructure. This achievement represents a leap forward in network innovation, sustainability, and sovereignty.
NXON.ai stands at the forefront of Asia's AI future—delivering speed, stability, and sovereignty in every packet transmitted.
NXON.ai builds next-generation AI infrastructure, integrating GPU clusters, high-speed networks, and orchestration technologies to empower sovereign and enterprise AI ecosystems across Asia.
For more information, visit www.nxon.ai.